Linux
Come usare htmlq per estrarre contenuto da file HTML su Linux
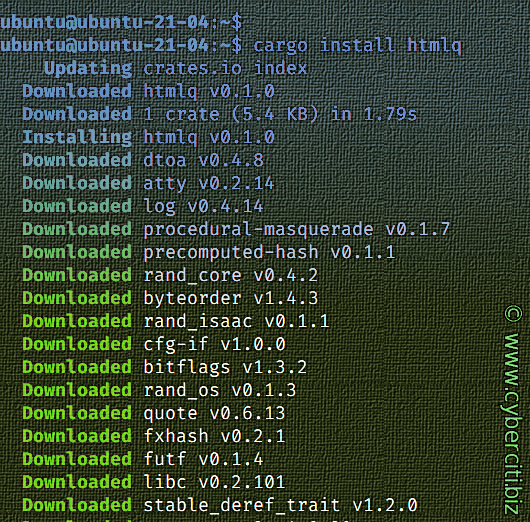
mLa maggior parte di noi usa l’amore e usa il comando jq. Funziona su sistemi simili a Linux o Unix per estrarre dati da documenti JSON. Recentemente ho trovato htmlq, che è come jq e scritto in Rust lang. Immagina di essere in grado di eseguire sed o grep per i dati HTML. Possiamo cercare, suddividere e filtrare i dati HTML con htmlq. Vediamo come installare e utilizzare questo pratico strumento su Linux o Unix e giocare con i dati HTML.
Che cos’è lo strumento htmlq?
È come jq, ma per HTML. Utilizza i selettori CSS per estrarre frammenti di contenuto dai file HTML. In CSS, i selettori vengono utilizzati per indirizzare gli elementi HTML sulle nostre pagine Web a cui vogliamo applicare lo stile. Ad esempio, possiamo estrarre facilmente le immagini o altri URL utilizzando questo strumento.
Installazione di htmlq su Linux o Unix
Ecco come installare cargo e rustc su Ubuntu o Debian Linux usando il comando apt/apt-get:sudo apt install cargo
Quindi eseguiresti:cargo install htmlq
Solo guide per i sostenitori di Patreon ????
- Nessuna pubblicità e tracciamento
- Guide approfondite per sviluppatori e amministratori di sistema su Opensourceflare✨
- Unisciti al mio Patreon per supportare i creatori di contenuti indipendenti e iniziare a leggere le ultime guide:
macOS durante l’installazione del carico
Apri l’app Terminale, quindi esegui il comando port come segue:sudo port install cargo
Oppure puoi installare Homebrew su macOS per utilizzare il gestore di pacchetti brew come segue:
brew install rustup # installs both cargo and rustc rustup-init rustc --version
Carico completo di FreeBSD
Userò il comando pkg come segue per installare rustc:sudo pkg install rust
Scopri come installare Rust per altri sistemi operativi. Ora che ho sia gli strumenti rustc che quelli cargo, digito il seguente semplice comando per ottenere htmlq sul mio sistema di sviluppo:cargo install htmlq

Hai installato Rust lang? Ora installa htmlq per divertimento e profitto usando il comando cargo.
Configura il tuo PERCORSO
Assicurati di aggiungere $HOME/.cargo/bin alla tua variabile PATH per poter eseguire i binari installati usando il comando export
# sh/bash/ksh etc export PATH="$PATH:$HOME/.cargo/bin" # tcsh/csh etc setenv PATH $PATH:$HOME/.cargo/bin
Come usare htmlq per estrarre contenuto da file HTML su Linux o Unix
Usiamo il comando curl per trovare parte di una pagina per ID:curl -s url | htmlq '#css-selector'
curl -s url2 | htmlq '#css-selector'
curl -s https://www.cyberciti.biz/faq/ | htmlq --pretty '#content' | more

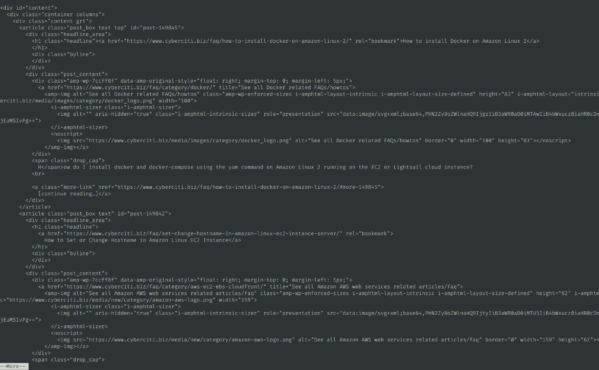
clicca per ingrandire
Troviamo tutti i link in una pagina. Per esempio:
curl -s https://www.nixcraft.com | htmlq --attribute href a
Ricevere aiuto
Esegui semplicemente:htmlq --help
htmlq 0.0.1
Michael Maclean <michael@mgdm.net>
Runs CSS selectors on HTML
USAGE:
htmlq [FLAGS] [OPTIONS] <selector>...
FLAGS:
-h, --help Prints help information
-w, --ignore-whitespace When printing text nodes, ignore those that consist entirely of whitespace
-p, --pretty Pretty-print the serialised output
-t, --text Output only the contents of text nodes inside selected elements
-V, --version Prints version information
OPTIONS:
-a, --attribute <attribute> Only return this attribute (if present) from selected elements
-f, --filename <FILE> The input file. Defaults to stdin
-o, --output <FILE> The output file. Defaults to stdout
ARGS:
<selector>... The CSS expression to select
Riassumendo
L’htmlq è davvero uno strumento adorabile e mi è piaciuto molto. Controlla il codice sorgente di Github. Provalo e fammi sapere cosa ti piace nella sezione commenti qui sotto.
ANNUNCIO
Ti e piaciuto questo articolo?
Supporta il mio lavoro, facendo una donazione!

Come suonare musica ambientale su iPhone
Come installare Xed su Kubuntu

MacOS Sonoma 14.7.5 e MacOS Ventura 13.7.5 Aggiornamenti di sicurezza rilasciati

Come disattivare le categorie di posta su iPad

iOS 16.7.11, iOS 15.8.4 e iPados 17.7.6 Aggiornamenti di sicurezza rilasciati per iPhone e iPad più vecchi

Guida all’installazione di AppImageLauncher su Kubuntu 24.04
Aggiornamento iOS 18.3.2 rilasciato con correzioni di bug

Quanto tempo impiega l’aggiornamento a MacOS? Perché l’aggiornamento MacOS sta impiegando così tanto tempo?

Come mostrare il codice QR per Wi-Fi su iPhone, Mac, iPad

Ottieni gli occhi googly nella barra del menu Mac per seguire il tuo cursore in giro
-

 Apple4 anni ago
Apple4 anni agoNon riesci a scaricare app su iPhone o iPad? Ecco come risolverlo
-

 Apple4 anni ago
Apple4 anni agoIl microfono dell’iPhone non funziona? Ecco come risolvere e risolvere i problemi del microfono di iPhone
-

 Apple4 anni ago
Apple4 anni agoCome disattivare la suoneria per un singolo contatto su iPhone con un trucco suoneria silenzioso
-
 Apple4 anni ago
Apple4 anni agoCorreggi l’errore “Impossibile installare l’aggiornamento” per iOS e iPadOS