Linux
Come Leggere un File Riga per Riga in Bash
Apple2 giorni ago
Rilasciati gli aggiornamenti di MacOS Sequoia 15.7.2 e MacOS Sonoma 14.8.2

Apple6 giorni ago
Come regolare il vetro liquido sulla schermata di blocco dell’iPhone
Apple1 settimana ago
Correzione dell’errore “Civilization 6 è danneggiato” su Mac
Apple1 settimana ago
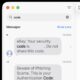
Metti in ordine i messaggi eliminando automaticamente i codici di verifica su iPhone, Mac, iPad
Apple2 settimane ago
Porta la neve che cade e le luci di Natale sul Mac con Snowy

Apple3 settimane ago
Aggiornamento iOS 26.2 rilasciato per iPhone e iPad

Apple3 settimane ago
Aggiornamento MacOS Tahoe 26.2 rilasciato per Mac

Apple3 settimane ago
Rilasciati gli aggiornamenti di sicurezza per iOS 18.7.3 e iPadOS 18.7.3
Apple3 settimane ago
Rilasciati gli aggiornamenti di sicurezza per MacOS Sequoia 15.7.3 e MacOS Sonoma 14.8.3
Apple4 settimane ago
Rendi evidente la tua finestra attiva in primo piano su MacOS Tahoe con Alan
-

 Apple5 anni ago
Apple5 anni agoNon riesci a scaricare app su iPhone o iPad? Ecco come risolverlo
-

 Apple5 anni ago
Apple5 anni agoCome disattivare la suoneria per un singolo contatto su iPhone con un trucco suoneria silenzioso
-

 Apple5 anni ago
Apple5 anni agoIl microfono dell’iPhone non funziona? Ecco come risolvere e risolvere i problemi del microfono di iPhone
-
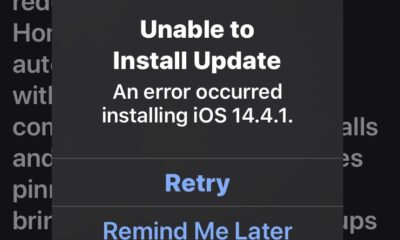
 Apple5 anni ago
Apple5 anni agoCorreggi l’errore “Impossibile installare l’aggiornamento” per iOS e iPadOS